

Avec l’arrivée de l’informatique, des réseaux, puis d’Internet, les vols d’informations physiques se sont peu à peu transformés en intrusions informatiques. Face à ce constat, Il devient donc essentiel que les données stockées sur des serveurs soient suffisamment protégées et sécurisées. Les scénarios d’attaques et d’intrusions vont consister à détecter les failles et les vulnérabilités en amont et obtenir un aperçu du niveau de sécurité du système d’information.
Cependant, comment permettre à des systèmes de détection d’intrusions de détecter des attaques, autrement dit, comment détecter des attaques et d’intrusions dans le système informatique ? C’est dans ce cadre que le thème « Scenarios d’attaques et d’intrusions dans une entreprise : étude et solution » nous a été confié. Ainsi, dans l’étude de ce thème, nous allons dans le chapitre 1 présenter l’UVCI, depuis sa création, jusqu’à ces missions en passant par son organisations interne. Puis, dans le chapitre 2, nous allons étudier des scénarios plus évolués et complexes, mettant en œuvre plusieurs phases d’approche puis d’attaque à des niveaux différents du SI. Finalement, dans le chapitre 3, nous présenterons alors la solution comme les SIEM 4, des outils qui permettent de corréler les informations de plusieurs IDS, ainsi que les avantages qu’ils apportent dans la détection de ce type d’attaques.
CONTEXTE DE REALISATION DU STAGE
- L’Entreprise
L’Entreprise qui m’accueil est l’Université Virtuelle de Côte d’Ivoire (UVCI) qui est une université publique crée par décret N°2015-777 du 09 décembre 2015 par l’Etat de côte d’ivoire. L’UVCI a pour principale mission de développer et vulgariser l’enseignement à distance à travers les Technologies de l’Information et de la Communication qui font partie intégrante du Programme Thématique de Recherche du Conseil Africain et Malgache pour l’Enseignement Supérieur (CAMES). Par conséquent, elle se doit d’accompagner les Universités et Grandes Écoles Publiques qui dispensent de cours en présentiel, afin que celles-ci convergent vers la formation à distance à travers le numérique.
Elle offre des formations qualifiantes, diplômantes et professionnalisantes.
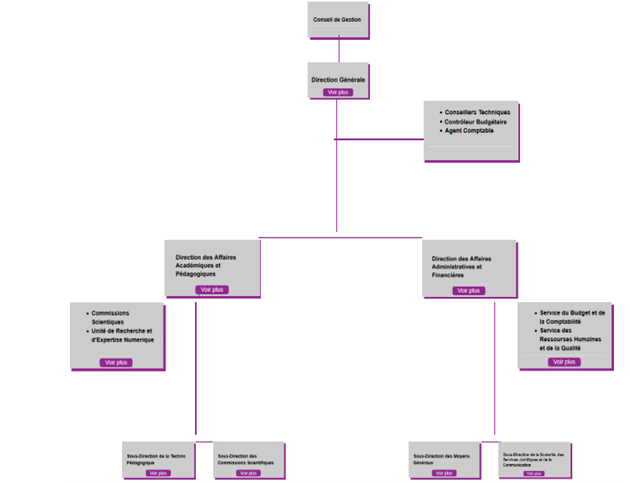
Figure 1 : Organigramme de de l’Université Virtuelle de Côte d’Ivoire
La direction des affaires académiques et pédagogique s’articule autour de 2 services :
- La Commissions scientifiques, qui fait notamment au conseil de gestion toute recommandation qu’elle juge utile sur les orientations de recherche des centres en tenant compte des attentes formulées par les pouvoirs publics
- L’Unité de recherche et d’expertise numérique (UREN), qui est spécialisée en sécurité des systèmes d’information, analyse et gestion du risque, définition des politiques et objectifs de sécurité, pilotage SSI (Sécurité du Système d’Information), audit de sécurité et mise en œuvre et exploitation d’infrastructures de sécurité.
Bien que l’UVCI soit déjà fragmentée en différentes services, l’unité de recherche et d’expertise numérique possède elle-même plusieurs équipes, travaillant sur des sujets différents.
Une équipe participe à des missions de conseil en sécurité organisationnelle, notamment en évaluation et management du risque, au niveau de la réduction des risques liés à la sécurité du SI, ou au pilotage des solutions SSI.
Une autre équipe intervient sur des missions d’audit de sécurité, permettant ainsi de contrôler et d’apporter des conseils afin de maximiser la sécurité des applications et installations évaluées. A l’heure actuelle, la majorité des activités consistent à auditer des applications Web ou mobiles.
Enfin, le pôle sécurité propose également une offre de management de la sécurité du système d’Information. Cette offre repose sur la conception, le déploiement et l’intégration de solutions de Supervision et de Management de la sécurité du SI (notamment au travers d’un SIEM), ainsi que la mise en place d’un « SOC » (Security Operating Center), qui permet au client d’externaliser la gestion de ses alertes de sécurité aux équipes de l’UREN
C’est au sein de cette équipe que j’ai effectué mon stage, dont les objectifs ou cahier de charge sont présentes dans la partie suivante.
2.1 Objectifs du stage ou cahier de charge
Depuis plusieurs années, L’UREN a développé une expertise forte sur des solutions de supervision de l’état de sécurité d’un SI. Cette supervision s’effectue notamment au moyen de Systèmes de Détection d’Intrusions (ou IDS) placés à plusieurs endroits du SI.
Ces IDS agissent et détectent les activités malveillantes à partir d’une base de signatures des comportements suspects (ou, à l’inverse, à partir d’une liste des comportements autorises). Ces signatures doivent donc être maintenues à jour afin de garantir un bon niveau de protection. Ces signatures sont généralement spécifiques a des outils d’attaques, ou à des scenarios d’attaques plus évoluées lancées contre la cible.
Les premiers points de mon cahier de ce stage sont de déterminer une liste d’outils fréquemment utilisés dans des audits ou des attaques. Ensuite, j’ai cherché à analyser de façon précise le fonctionnement de ces outils ainsi que les traces qu’ils peuvent laisser sur le réseau ou sur le système afin de pouvoir les détecter.
Aussi, j’ai cherché à atteindre un niveau supérieur en détectant des attaques plus complètes, en construisant des scénarios complets. Ces scénarios se composent de plusieurs phases, pouvant utiliser plusieurs outils. Ici aussi, la détection complète de ce scénario est nécessaire afin d’assurer un niveau de détection le plus avancé possible en étant au plus proche de l’état de l’art actuel. J’ai donc cherché à proposer des scénarios réalistes, utilisés « dans la nature » contre des systèmes d’information d’entreprises. Enfin, ce cahier de charge devait également me permettre de monter en compétences sur plusieurs sujets, en particulier la détection d’intrusions, réalisée à plusieurs niveaux dans l’infrastructure d’un SI. De plus, il est possible d’obtenir un niveau de supervision plus élevé en utilisant les IDS ensemble et en corrélant les informations de chacun. L’apprentissage des solutions de type SIEM a donc été une part importante du stage. Je m’attarderai donc sur l’implémentations de ces scénarios au niveau des configuration des différents outils et au niveau des règles de détection associées.
CONCEPTION
DETECTION D’INTRUSIONS
Pour débuter ce rapport, je vais présenter de façon générale la détection d’intrusions afin de poser les bases nécessaires à la bonne compréhension des techniques présentées plus après.
Je commencerai cette partie par une introduction à la sécurité informatique, afin de donner les notions et le vocabulaire récurrents liés à la détection d’intrusions.
Je poursuivrai ce rapport en décrivant la détection d’intrusions d’un point de vue théorique. J’aborderai notamment les caractéristiques des IDS, leur fonctionnement et les résultats attendus de ceux-ci.
Enfin, je terminerai cette partie par la présentation des différents outils utilisés en entreprise, et plus particulièrement par ceux utilisés lors de mon stage.
2.1 La Sécurité Informatique
Avant de pourvoir entrer dans le vif du sujet, il est important de poser quelque notion de base de l’informatique, et notamment sur la sécurité informatique, puisque les travaux concernant la détection d’intrusions sont en partie des sciences informatiques.
2.1.1 Sécurité Informatique : La protection des données
On peut définir la sécurité informatique comme suit : La sécurité informatique est l’ensemble des moyens techniques, organisationnels, juridiques et humains nécessaires et mis en place pour conserver, rétablir, et garantir la sécurité des systèmes informatiques. Elle est intrinsèquement liée à la sécurité de l’information et des systèmes d’information.
Bien que cette définition soit complète, elle utilise deux notions qu’il convient également de définir. Je vais donc définir la sécurité, et plus précisément la sécurité informatique, puis je détaillerais ce que l’on entend par informatique dans cette définition.
De manière générale, la sécurité informatique consiste à mettre en place et maintenir des techniques permettant de garantir que les ressources informatiques sont utilisées uniquement dans le cadre prévu par la Direction des Systèmes d’Informations. On doit ainsi maîtriser les 3 enjeux suivants :
La Confidentialité : Seules les personnes autorisées doivent pouvoir accéder aux ressources informatiques ;
J’utilise ici, par abus de langage, le terme « personne » pour désigner les entités qui ont accès aux ressources. En réalité, ce terme englobe les utilisateurs, les processus, les applications, etc…
L’Intégrité : Seules les personnes autorisées doivent pouvoir modifier les ressources informatiques ;
La Disponibilité : Les personnes autorisées doivent pouvoir accéder à tout instant aux ressources proposées ;
A cela, on peut également rajouter les 2 enjeux suivants, qui permettent d’atteindre un niveau de sécurité plus important :
La Non-répudiation : Une personne ne peut contester avoir effectuer des actions sur les ressources informatiques ;
L’Imputation : Il doit être possible, à tout instant, d’identité la personne qui aura effectué une action sur les ressources.
La sécurité informatique consiste donc à s’assurer, qu’à tout instant, les 5 propriétés précédentes des ressources informatiques sont assurées.
2.1.2 La Sécurité Informatique : La protection contre les attaques
- Description de la méthode
J’ai donné dans la partie précédente une définition de la sécurité informatique. Cependant, bien qu’ayant présente ce qu’était la sécurité, je n’ai pas abordé un point important : contre quoi est-il important de se protéger ?
Mettre en place une sécurité forte sur son Système d’Information a pour objectif d’empêcher, ou au moins de limiter, les intrusions sur le SI. Une intrusion est une violation de la politique de sécurité mise en place. Nous parlons alors d’une attaque lancée contre le système.
- Description et choix des outils techniques
La suite des différentes phases de l’attaque compose le scénario de l’attaque. Dans la majorité des cas, nous tenterons de détecter une attaque en décelant chacune des étapes séparément. Le comportement juge « anormal », engendre par l’intrusion elle-même par rapport à l’activité « normale » du système constitue la signature de l’attaque.
Une attaque informatique est la tentative d’exploitation d’une faille, ou vulnérabilité afin de procéder à une intrusion dans le SI. Ces vulnérabilités peuvent être de plusieurs types, et sont généralement des défauts de conception, de mise en place ou d’administration des différentes parties du système d’information

Figure 2 : Matrice de risques : Evolution du risque en fonction de l’exploitabilité d’une faille et des conséquences de l’exploitation
Une attaque est donc la tentative d’exploitation d’une faille sur une partie du système.
Cette partie se nomme également un actif, ou asset. En sécurité, l’objectif est donc de chercher à se protéger des risques qui peuvent impacter les actifs du SI.
Le risque est fonction des menaces qui pèsent sur les assets. Ainsi, plus les vulnérabilités sont facilement exploitables et plus les conséquences de l’intrusions critiques pour l’activité, alors plus le risque sera élevé.

Figure 3 : Diagramme d’évaluation du niveau de risque d’un périmètre.
La matrice donnée en figure 2 présente l’évolution du risque en fonction de la criticité de l’exploitation d’une vulnérabilité, ainsi que la facilité d’utilisation de celle-ci.
3. La réalisation
3.1 Approche théorique à la détection d’intrusions
Après avoir présenté succinctement dans la première partie ce qu’était la sécurité informatique, je vais désormais faire de même pour la détection d’intrusions.
Je commencerai cette présentation en énonçant les différents enjeux de la détection d’intrusions du point de vue de la DSI.
Enfin, je terminerai cette partie par une présentation des différents outils disponibles sur le marché de la détection d’intrusions, ensuite les difficultés que j’ai rencontrées et les enseignements que j’ai pu tirer lors de mon stage.
3.1.1 Caractéristiques des IDS
Un système de détection d’intrusions complet se compose de nombreuses parties, chacune ayant une tâche précise et essentielle dans le processus de détection.
Nous pouvons distinguer les différents blocs suivants :
–Les sources de données, à partir desquelles on vérifiera si une intrusion est en cours ; C’est l’élément indispensable a tout système de détection d’intrusions est son panel de sources de données. En effet, c’est sur cette base que la totalité du système va se construire et la précision des données reçues de ces sources va conditionner la justesse des alertes émises par l’IDS.
–Le moteur de détection, qui va analyser les données reçues des sources précédentes afin de remonter des événements ; Ce moteur peut se baser sur deux approches d’analyse :
- Une approche par signature
- Une approche comportementale
–La réponse à la détection, suite aux événements remontes par le moteur de détection, le système pourra choisir d’exécuter une action spécifique en réponse. L’objectif de la détection d’intrusion est de détecter les intrusions, et surtout d’agir en réponse afin de limiter les actions qui peuvent être réalisées par l’attaquant.
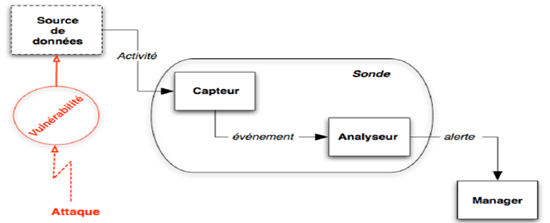
Figure 4 : Architecture d’une plateforme de détection d’intrusions. Article issu de l’article
[BHM+06]
3.1.2 Propriété attendues des IDS
Les principaux enjeux de la détection d’intrusions, du point de vu de la DSI, sont de surveiller le niveau de sécurité du SI et de savoir, en temps réel, si des attaques sont en cours et si elles aboutissent ou non.
La première propriété attendue des IDS est d’apporter les informations les plus précises concernant les intrusions en cours. Notamment, nous cherchons à nous assurer que les alertes remontées soient fiables et pertinentes.
De la même façon, il est important qu’une alerte ne soit levée que si, et seulement si, une attaque est en cours, afin de réduire le temps de traitement des événements non désirés.
Le taux de faux positifs (alertes remontes sans cause réelle d’attaque) doit également être le plus bas possible.
Par exemple, si on choisit de créer des alertes pour chaque action entreprise sur le SI, le nombre de faux négatifs va très fortement baisser, puisque chaque opération, légitime ou non, aura pour conséquence la création d’une alerte. Cependant, les faux positifs seront en très grand nombre. A l’inverse, en ne remontant que très peu d’alertes il est possible de diminuer la quantité de faux négatifs, puisque seuls les cas très avérés d’attaques engendreront des événements de sécurité. Cependant, on s’expose également à laisser passer des cas d’attaques plus larges qui n’auront pas été prise en compte.
L’un des plus grands défis de la détection d’intrusions est ici. S’assurer que les alertes ne sont causées que par des attaques réelles, et que dans le même temps chacune des attaques remonte des alertes aux administrateurs.
Je présenterai dans la partie suivante les 3 principaux outils que j’ai utilisé au cours de ce stage.
4) Principaux IDS
Les systèmes de détection d’intrusions sont multiples, et adaptés au type de données que l’on souhaite analyser.
Il est possible de retenir que deux grandes familles d’IDS :
- Les Network-Based Intrusion Detection System, ou NIDS, qui analysent des flux réseaux afin d’en tirer des informations ;
- Les Host-Based Intrusion Detection System, qui se basent sur des informations provenant du système d’exploitation.
J’ai principalement utilisé, au cours de mon stage, 3 IDS.
Le premier, Snort, est un NIDS utilisant une approche de détection par signatures.
Il écoute la trace d’une interface réseau et remonte des événements si des paquets correspondent à une de ses signatures.
Le deuxième système de détection d’intrusions utilisé est OSSEC. A la différence de Snort, c’est un Host-based Intrusion Detection System. Au lieu de surveiller de tracé le réseau, il se base sur des actions effectuées sur le système d’exploitation pour générer des événements de sécurité.
Enfin, j’ai également utilisé Audit, un HIDS dédie aux systèmes GNU/Linux. Celui-ci permet d’obtenir des informations précises sur les accès, par des utilisateurs ou des applications, a des fichiers ou répertoires de l’OS.
Je vais, dans la suite de ce chapitre, présenter ces trois systèmes de détection d’intrusions plus en détails, en insistant sur leur fonctionnement global, ainsi que sur le format des signatures qu’ils utilisent.
4.1 Snort
Comme je le mentionnais en introduction à cette partie, Snort est un outil de détection d’intrusions basé sur le réseau.
Il analyse donc la totalité des données réseaux utilisant le protocole IP. Ensuite, il analyse chacun des paquets reçus, et effectue une action si ceux-ci correspondent à une des règles définies.
Snort peut effectuer plusieurs actions à la réception d’un paquet jugé malicieux. La première action, la plus commune, est de créer un événement afin d’alerter les administrateurs. Il est également possible d’effectuer d’autres actions, comme loguer les paquets reçus, activer d’autres règles Snort, bloquer les paquets, ou encore rejeter la connexion (en envoyant un paquet TCP reset ou ICMP port unreachable).
Dans cette dernière configuration, dans laquelle Snort bloque les paquets qui correspondent à ses règles, il ne se comporte plus comme un IDS, mais comme un IPS, ou Intrusion Prevention System. Dans cette configuration, au lieu de simplement détecter les intrusions, Snort réagit de façon active aux intrusions en les bloquant au moment où elles apparaissent.
Les règles Snort étant basées sur la signature des paquets illégitimes, le moteur de Snort doit être capable d’analyser le contenu des flux réseaux. Afin de réaliser cette opération, Snort dispose donc d’un ensemble de décodeurs lui permettant d’analyser intrinsèquement le contenu des flux.
Les décodeurs accessibles sont :
- TCP
- UDP
- ICMP
- IP
Cela signifie qu’il est donc possible d’écrire des règles Snort en fonction des valeurs de certains champs ou options spécifiques au protocole utilisé.
Grâce à ses décodeurs, les règles Snort peuvent donc être très précises.
La base des signatures sont les source et destination du flux, à savoir les adresses IP et ports utilisés. Ensuite, les règles s’affinent, en intégrant des précisions sur le contenu des paquets.
En règle générale, la détection se basera sur le contenu du paquet. Il est donc possible d’utiliser le mot-clé content: » » de Snort pour devenir une chaîne de caractères qui doit être présente dans le paquet pour lever une alerte. Ce motif peut également être une expression régulière, plutôt qu’un contenu défini « en dur », au moyen du mot clé pcre
La règle peut ensuite contenir des informations beaucoup plus précises sur le contenu du flux, ou sur le positionnement de ces motifs dans le paquet. Notamment, Snort peut décoder plus précisément le trafic HTTP et il est possible de lui demander de ne rechercher des motifs que dans les cookies HTTP, dans les entêtes ou l’URI, ou encore filtrer sur des méthodes HTTP ou sur des codes de réponses particuliers. Enfin, les règles Snort peuvent également filtrer sur des numéros de séquences TCP, ou sur des id de datagrammes IP.
Exemples de règles : Afin de mieux observer le principe de construction des règles
Snort, je vais présenter ici, quelque règles simples et plus avancées au travers d’un exemple simple : détecter une injection SQL basique.
Cette première règle lève une alerte identifiée par le numéro 999001 et par le message SQL Injection si Snort détecte que la chaîne de caractères SELECT * FROM est transmise au serveur web sur le port tcp/80 ($WEB_SERVER est une variable Snort qui contient l’adresse
IP du (ou des) serveur(s) Web). La nouvelle version de la règle donnée ci-dessous apporte quelques précisions, tout en étant plus souple sur la détection. On précise que la connexion TCP doit être établie (flow:established), à destination du serveur (flow:established,to_server😉 (ici $WEB_SERVER).

Listing 1 : Exemple de règle Snort : Détection d’une injection SQL.
Enfin, on assouplit la règle en effectuant une recherche de la chaîne SELECT * FROM non sensible à la casse des caractères (nocase;), mais en spécifiant qu’elle doit se trouver dans l’URI de la requête HTTP. On ajoute également un type à l’alerte, afin de faciliter le tri par les équipes d’exploitation des incidents.

Listing 2 : Exemple de règle Snort : Détection d’une injection SQL, version 2.
Snort est un NIDS performant, capable de traiter de grandes quantités d’événements, et disposant d’un jeu de règles évolué permettant d’obtenir des informations très précises sur les incidents en cours sur le réseau.
Cependant, ses données ne fournissent des renseignements que si les intrusions utilisent le réseau, durant la phase d’infection ou d’exploitation. Pour monitorer des incidents différents, il faut utiliser d’autres types de systèmes de détection d’intrusions, comme les HIDS.
4.2 OSSEC
A la différence de Snort, OSSEC est un système de détections d’intrusions basé sur les systèmes d’exploitation plutôt que sur le réseau. Au cours de mon stage, j’ai travaillé sur les versions Microsoft Windows et GNU/Linux d’OSSEC.
OSSEC a un mode de fonctionnement typique d’un IDS. Des agents sont déployés sur chacun des systèmes à monitorer et s’occupent de collecter les informations importantes.
Ensuite, toutes les données sont centralisées sur un serveur OSSEC chargé de les analyser. Les agents OSSEC ont la particularité de traiter principalement des fichiers de logs.
Bien qu’il soit considéré comme un HIDS, il est également possible de le classer parmi les LIDS : Logs-Based Intrusion Detection System. Il dispose d’une liste des différents journaux d’événements à surveiller, et les agents transmettent au serveur toute nouvelle entrée dans ces fichiers.
Cependant, les agents OSSEC disposent également d’autres fonctionnalités. Ils sont capables de réaliser des contrôles d’intégrité sur des fichiers et répertoires et sur des clés de Registre Windows, afin de pouvoir alerter à chaque modification des informations sensibles.
Les agents disposent également d’un système de détections des rootkits qui pourraient modifier des fichiers critiques de l’OS.
La première étape de détections dans une infrastructure OSSEC est donc le décodage de ces logs. Ensuite, on peut écrire des règles génériques ne s’appuyant que sur ces logs décodés.
Le fonctionnement interne d’un serveur OSSEC, et plus précisément son moteur de détections, est basé sur un format standard de stockage et de gestion des événements. Les données reçues sont manipulées par des décodeurs qui, au moyen d’expressions rationnelles, vont extraire les informations importantes et nécessaires à la détection, et les stocker dans des variables internes à OSSEC.
Les signatures définies dans les règles sont donc basées sur ces variables. Des alertes sont levées si les variables extraites des logs correspondent aux valeurs définies dans la règle.
Exemples de règles : Tout comme pour Snort, je vais donner ici un exemple de configuration basique permettant de détecter tous les accès à des pages non présentes sur le site Web (code HTTP 404).
La configuration s’effectue en 2 parties. La première est la configuration de l’agent afin qu’il relève toute modification du fichier de logs du serveur Web présent sur la machine
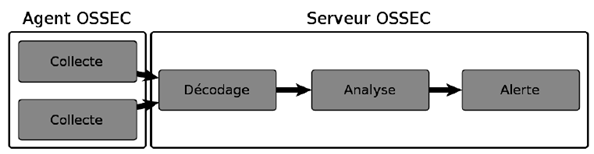
Figure 5 : Processus de traitement d’un incident par OSSEC.
Image tirée de la documentation OSSEC : http://www.ossec.net

Listing 4 : Exemple de règle OSSEC : Configuration de l’agent pour le monitoring des logs Apache.
Les événements récupérés par les agents Snort doivent être décodés afin de pouvoir écrire des règles sur ces contenus. Un décodeur OSSEC est très simple, il contient une expression régulière qui extrait des valeurs, et le nom de variables auxquelles affecter ces valeurs.
Dans notre cas, on extrait du log Apache : l’adresse IP source, la méthode HTTP, l’URI demandée et le code de retour HTTP.



Listing 6 : Exemple de règle OSSEC : Création de règles serveur pour les logs Apache.
Malgré qu’il nécessite une architecture de type client/serveur, OSSEC est très simple à déployer et mettre en place. Il intègre en effet un système de gestion centralisé des configurations et de déploiement automatique de la configuration sur les agents. J’ai tout de même trouvé une limite à OSSEC. Il est capable de détecter les modifications apportées à un fichier, mais pas de détecter les autres types d’accès (lecture, exécution). On doit pour cela utiliser d’autres IDS, et j’ai utilisé pour ma part Audit, un HIDS dédie aux systèmes GNU/Linux.
4.3 Audit
Sur les systèmes GNU/Linux, Audit est un système de détections d’intrusions qui permet de monitorer les accès à certains fichiers du système, en obtenant dans les journaux d’événements des informations très précises sur le type d’accès au fichier, l’utilisateur qui réalise cet accès et d’autres informations plus précises, comme l’application qui est utilisée pour réaliser l’accès, le succès (ou non) de la tentative d’accès, etc…
Le fonctionnement d’Audit est très simple. Dans un fichier de configuration, il est possible de configurer le chemin d’accès au fichier, les types d’accès pour lesquels lever des alertes, et d’autres paramètres permettant d’affiner les cas dans lesquels créer des incidents. Le module noyau d’Audit intercepte ensuite tous les appels systèmes et lève des incidents si un de ceux-ci correspond aux règles définies dans le fichier de configuration.
Exemples de règles : L’exemple de règle suivant génère des événements à chaque accès par l’utilisateur www-data (utilisateur qui lance le serveur Web Apache sur le système) accède en lecture, écriture ou modification au fichier /etc/passwd (contenant les noms d’utilisateur et mots de passe) de l’OS.

Listing 26 : Règle Audit de détections des accès en lecture ou écriture au fichier /etc/passwd par l’utilisateur www-data (uid:33).
De cette manière, on retrouve dans la console du SIEM, ou dans les logs bruts des IDS, deux événements. Le premier, émis par Snort, et le second par le couple Audit/OSSEC qui détecte l’accès au fichier. L’objectif de la « double détections » étant de diminuer le nombre de faux positifs, on cherche également à n’avoir qu’une seule alerte de sécurité par intrusion ou attaque.
Il est donc possible d’utiliser les directives de corrélation d’un SIEM comme OSSIM, qui ont deux avantages.
En premier lieu, ils permettent de corréler les événements de plusieurs IDS, ou plus généralement de différentes sources de données, pour ne lever qu’une alerte de sécurité, plus précise.
Ensuite, les directives de corrélation d’un SIEM peuvent ajuster le niveau de criticité des alertes levées en fonction des événements qui apparaissent au cours du temps.
La directive de corrélation écrite pour les attaques LFI se décompose en 3 niveaux.
Au moment de la détections par Snort du payload de l’attaque, le SIEM génère une alerte de niveau 4.
A ce moment-là, OSSIM se place en attente de l’événement provenant d’OSSEC. S’il obtient, dans une période de temps définie, l’événement correspondant à l’accès au fichier /etc/passwd, le SIEM va remonter la criticité a 8, car il obtient la confirmation que l’attaque est réellement en cours.
Si aucun événement Audit/OSSEC n’est levé, alors la criticité est placée à 5, car une attaque a été lancée contre un site Web monitoré, sans toutefois être effective.
5) Détection avancée d’attaques lancées par des outils automatiques
La corrélation d’événements de sécurité peut être utile, comme je viens de le montrer, pour détecter une attaque Web générique. Il est également possible d’utiliser les SIEM pour détecter avec plus de précision les attaques lancées par des outils d’audit.
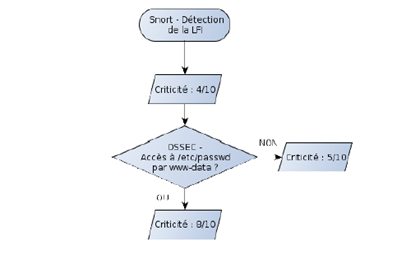
Figure : Schéma d’évolution du niveau de criticité d’une attaque Web de type LFI.
Un outil très utilisé est le proxy Burp. Il est capable d’intercepter les requêtes envoyées aux serveurs Web audites, de les modifier, et surtout de réutiliser ces requêtes comme des « modèles », afin de lancer des scans de vulnérabilités sur ces applications, en utilisant des requêtes paraissant légitimes.
Burp étant un outil très utilisé par les auditeurs et les attaquants, je me suis également penché sur son fonctionnement afin de tenter de le détecter.
Le module scanner de Burp est un scanner de vulnérabilités comme WebSecurify ou XSSer. Il tente d’injecter sur l’application attaqué de nombreux payloads, pour déterminer si un ou plusieurs vulnérabilités sont présentés.
La première piste de réflexion concernant la détection avait été de rechercher un motif connu dans les paquets reçus, comme le User-Agent par exemple. Cependant, Burp utilise comme base à toutes ses requêtes une des requêtes effectuées par le navigateur de l’auditeur sur l’application auditée. Il est donc impossible d’utiliser cette méthode. La deuxième technique est de rechercher des payloads spécifiques à Burp dans les requêtes réalisées sur le site Web. J’ai donc choisi d’utiliser les performances du moteur de corrélation d’OSSIM afin de détecter avec efficacité le scanner de Burp. Il est possible d’écrire une règle Snort pour un payload donné de Burp. En revanche, il est possible que ce payload ne soit pas utilisée lors du scan des vulnérabilités.
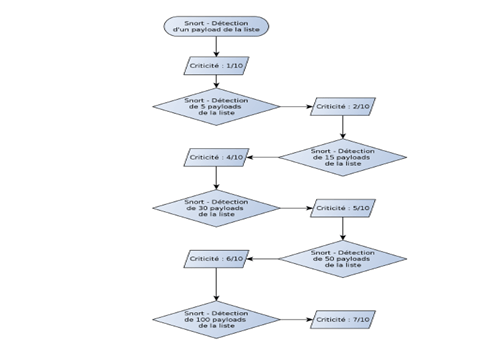
Figure : Schéma d’évolution du niveau de criticité d’une attaque lancée avec le scanner de Burp.
De cette façon, à chaque attaque utilisant le scanner de Burp, un certain nombre d’alertes seront remontées par Snort. Plus ce nombre est important, plus la probabilité que l’attaque soit réellement lancée avec Burp sera grande.
C’est ce principe que j’ai choisi de mettre en pratique au cours de mon stage. J’ai établi une liste des payloads les plus fréquemment utilisés par le scanner de Burp

Listing : Règle Snort de détections basique d’une payload utilisé par le scanner de Burp.
5.1 Détection d’une attaques « générique »
Une attaque lancée contre un SI se compose généralement de deux phases. Une phase de reconnaissance, pendant laquelle l’attaquant tente d’obtenir le plus d’informations possibles sur sa cible, puis la phase d’attaque à proprement parler.
Un exemple d’attaque peut donc se constituer d’un scan nmap sur une (ou des) machine(s) du SI, afin de déterminer les différents services ouverts sur celle-ci, puis de tentatives d’intrusion sur le service SSH (par un brute force pour trouver le nom d’utilisateur, puis l’exploitation d’une faille connue par exemple).
J’ai ici choisi de présenter des attaques sur SSH, mais le fonctionnement de la détection est très simplement adaptable à tout autre service Web.
La première partie de l’attaque est un scan nmap. Comme je l’expliquais précédemment, il est complexe de détecter cet outil avec un NIDS seul, tel que Snort. Cependant, dans le cadre d’une détection plus avancée, mettant en place un SIEM, il est possible de mettre en place une règle Snort générique, qui se base sur le nombre de connexions réalisées en une courte période de temps, et la présence de certains flags dans les paquets TCP.
Un exemple de règle Snort de détections d’un scan SYN est donné dans le listing suivants. Elle ne lève une alerte qu’après avoir reçu 150 paquets SYN, en 20 secondes, provenant de la même IP source.

Listing 28 : Règle Snort de détections d’un scan SYN effectuée par nmap.
Dans les parties de ce rapport, j’ai montré comment j’ai analysé des outils permettant de lancer automatiquement des attaques sur une application Web, puis j’ai présenté les différentes façons de les détecter au moyen de systèmes de détections d’intrusions, notamment d’un NIDS.
Ensuite, j’ai dressé une liste des limites de cette détections, en présentant comment il était possible pour un attaquant de lancer des attaques qui ne seraient pas détectées par les règles précédemment écrites.
Enfin, j’ai montré comment on pouvait dépasser certaines limites de la détection d’intrusions en utilisant conjointement plusieurs IDS, pour détecter de façon plus précise les attaques.
En conclusion de cette partie, je vais tenter de répondre à la question suivante :
5.2 La corrélation d’évènements et les SIEM sont-ils la solution miracle pour détecter toutes les attaques ?
Les SIEM permettent, comme je l’ai précisé plus haut dans ce rapport, de corréler des évènements provenant de nombreuses sources. Je n’ai présenté que des directives qui agrégeaient des logs issus de systèmes de détections d’intrusions, ou d’un lecteur de badge.
Les SIEM, et notamment OSSIM, sont également capables de recevoir et manipuler des événements provenant d’équipements réseaux, comme des commutateurs ou des routeurs, provenant d’équipements de sécurité, comme des proxys ou des pares-feux, ou encore provenant directement de certains services installés sur des machines, comme SSH, des logs d’authentification Windows, ou des logs de serveurs Web comme Apache par exemple.
Toutes ces sources permettent de surveiller et lever des alertes de sécurité précises, puisque le SIEM a accès à des informations provenant de plusieurs points du SI.
De plus, la multiplication des sources et des évènements permette d’écrire des directives de corrélation plus abouties, et donc de remonter des alertes plus précises et plus pertinentes, en se basant sur une base plus large et plus solide.
Malgré tout, les SIEM ne résolvent pas tous les problèmes. Pour qu’ils soient efficaces et que leurs alertes soient pertinentes, il est indispensable que les NIDS et HIDS soient correctement configurés, et que leurs règles de détections soient maintenues à jour au cours du temps. Si les IDS sur lesquels repose le SIEM ne remontent aucun évènement, ou si la quantité de faux-positifs est trop importante, les alertes émises par le SIEM ne seront pas plus pertinentes que les simples évènements des IDS.

Figure : Comparatif détaillé des fonctionnalités des NIDS, HIDS et SIEM.
De plus, la mise en place et le maintien en conditions opérationnelles d’un SIEM demande, approximativement, deux fois plus de ressources (en termes humains et temporels), puisqu’il faut maintenir le jeu de règles des IDS et les directives de corrélation du SIEM.
En conclusion, et suite aux nombreuses expérimentations et manipulations que j’ai pu effectuer au cours de mon stage, je pense que l’utilisation d’un SIEM au sein d’une architecture de détections d’intrusions facilite grandement la gestion des évènements de sécurité.
Les SIEM possèdent, en plus du moteur de corrélation, des fonctionnalités permettant de filtrer et limiter les évènements reçus en fonction des investigations effectuées, et possèdent également des fonctions de reporting et de navigation au sein des alertes de sécurité qui rendent leur traitement plus aisé.
Aussi, il faut garder à l’esprit que pour qu’un SIEM soit efficace et produise des alertes pertinentes, il faut que les IDS sur lesquels il se base soient correctement maintenus, que leurs règles soient à jour, et que les directives de corrélations doivent également être évaluées régulièrement.
Enfin, la conclusion permet de montrer qu’un SIEM a des avantages et facilite la gestion des événements de sécurité qui surviennent sur un SI, malgré que son utilisation ne résolve pas tous les problèmes inhérents à la détection d’intrusions.
5.3 Les Difficultés Rencontrés
Au début de mon stage, j’ai rencontré quelques difficultés.
Mon
manque d’expérience m’aura peut-être souvent handicapé, surtout quand il s’agissait
de prendre des décisions qui ne m’appartenaient pas forcément.
En effet, le manque de temps
ne m’aura pas permis une organisation suffisante afin de réaliser un travail
digne de ce nom.
Toutefois, en dépit de ces difficultés, mon stage m’a apporté de nombreuses
satisfactions et
savoir être.
5.4 Enseignement Tirés
Mon stage au sein de l’Université Virtuelle de Côte d’ivoire (UVCI) a été très positif car il m’a permis de développer et d’acquérir des savoir être qui sont utiles et indispensables dans le monde du travail.
Tout d’abord, mon stage m’a permis d’acquérir une plus grande confiance en moi.
Cela m’a permis de me réaliser en tant que personne voulant aider des populations en difficultés, et ainsi affirmer ma position en tant que désireux de vouloir m’impliquer dans une carrière professionnelle touchant ce milieu.
Au sein de l’entreprise, j’ai appris l’esprit d’équipe et qu’il était important de se confier, et ainsi apprendre des conseils des autres, notamment quand on se trouve dans un milieu inconnu qui montre énormément de différences avec la culture dont on est issu.
De plus, le travail qui m’avait été confié, était pour moi une vraie mission, ainsi qu’un vrai test, afin de savoir si j’étais capable de m’impliquer davantage dans cette voie, qui n’est pas sans difficultés.
Enfin, La rédaction de cet article a été un excellent exercice qui m’a permis de mettre en pratique les connaissances obtenues au cours de mon stage.
D’un point de vue non technique, la rédaction de cet article a été une bonne préparation à la rédaction de ce rapport, notamment dans la structuration des idées et l’enchaînement des parties.
CONCLUSION
Ce stage réalisé en entreprise à la fin de ma licence a été pour moi une grande réussite et m’a permis de mettre en pratique, de consolider les connaissances acquises lors de mon cursus universitaire et de mes recherches personnelles ensuite m’a aussi permis de réellement m’imprégner des activités et tâches qui nous attendent en entreprises.
Nous avons bénéficier de plusieurs contributions parmi lesquelles celles de notre encadreur monsieur ADJA Owo Serge Alain ainsi que tout le corps professoral de l’UVCI. Ces contributions portaient sur les explications de cours, de travaux pratiques et l’utilisation de logiciels spécifiques.
On pourra donc penser à améliorer notre solution car nous avons découvert, que d’autre entreprises utilisaient ce système avec des options plus améliorées que les nôtres.
Nous suggérons que, afin de rendre la formation plus complète à l’UVCI, de combiner les connaissances des différentes spécialités enseignées et de rendre plus pratique les cours liés à notre domaine de compétences.
CONCLUSION
Ce stage réalisé en entreprise à la fin de ma licence a été pour moi une grande réussite et m’a permis de mettre en pratique, de consolider les connaissances acquises lors de mon cursus universitaire et de mes recherches personnelles ensuite m’a aussi permis de réellement m’imprégner des activités et tâches qui nous attendent en entreprises.
Nous avons bénéficier de plusieurs contributions parmi lesquelles celles de notre encadreur monsieur ADJA Owo Serge Alain ainsi que tout le corps professoral de l’UVCI. Ces contributions portaient sur les explications de cours, de travaux pratiques et l’utilisation de logiciels spécifiques.
On pourra donc penser à améliorer notre solution car nous avons découvert, que d’autre entreprises utilisaient ce système avec des options plus améliorées que les nôtres.
Nous suggérons que, afin de rendre la formation plus complète à l’UVCI, de combiner les connaissances des différentes spécialités enseignées et de rendre plus pratique les cours liés à notre domaine de compétences.
